According to IBM, poor data quality costs the US economy $3.1 trillion a year. This figure includes lost opportunity costs and bad decisions based on faulty data. In IP (intellectual property), the direct costs of bad information can include multimillion dollar lawsuits with sky-high litigation fees, and the indirect costs of damaged reputations and lowered company valuation.
While there are many definitions of data quality, a common theme is that the data can be considered high quality if it works for its intended use in operations, decision making, or planning. For example, using Google Patents to find out which companies are the major players in hybrid automotive technology is a good fit. However, if a parts manufacturer needs a freedom to operate analysis performed before they launch a new hybrid automotive product, consulting a law or IP firm is more appropriate.
With new AI-based technologies such as text mining and machine learning, feeding these models high quality training data is critically important. It’s been estimated that data scientists spend 80% of their time cleaning and preparing data to build accurate models. A massive amount of information needs to be correctly labeled, deduplicated, and normalized. And the requirement doesn’t end there–new data fed into developed models for analysis also needs to be accurate, or else the end results will be wrong. Garbage in, garbage out!
It’s hard to find an industry or job function that isn’t trying to integrate smart algorithms for speeding up time consuming tasks and processes. Activities that are IP intensive are no exception. Many of our clients have built impressive platforms using our data as a backbone, including:
- Averbis – Using multiple forms of AI, Patent Monitor automates important IP activities, including patent landscaping, competitor analysis and relevancy checks.
- europatent – Building on 60 years of experience as an IP surveillance firm, PATOffice uses an advanced algorithm to score patent documents, helping customers focus on the most relevant patent documents.
- Linguamatics – Through natural language processing and text mining, I2E enables life sciences customers to ask questions and get actionable results ten times faster than keyword searching.
At IFI, we’re serious about providing the highest quality patent data available. Our data pipeline process takes raw data and transforms it into a uniform data format. When problems arise resulting from original records, we work with patent authorities to get to the root of the problem. We’re always on the lookout for further ways to improve quality, such as the recent introduction of a new Chinese machine translation source offering greater accuracy. As we improve and correct data, these changes are automatically integrated into our existing content.
The data enrichments we provide save clients time cleaning up and formatting data. Some of our most popular features are:
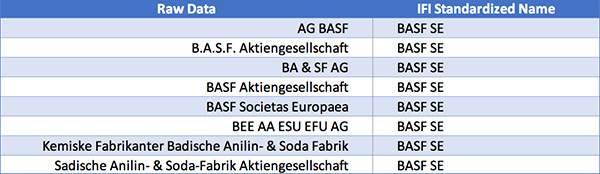
- Name standardization: There are more than 2,000 variations of the way IBM appears in patent records. We enhance our data with a common name to provide consistency.
- Patent status: Know if a patent is still in force, or in the case of applications, if the application is pending, granted, or inactive.
- Expiration dates with a unified format: Calculations are based on the original filing date and term extensions.
- Translations: Machine translations of non-English documents.
In order to produce the best analysis or product, high quality data must be the foundation. Learn more about our approach to quality.
