Re-indexing Data from CLAIMS Direct Data Warehouse
Introduction
There are a number of reasons one would need to re-index data from the data warehouse. These range from simply repeating a load-id to a complete re-index of the entire contents of the data warehouse. In this blog, I'm going to go over the mechanisms that move data from the data warehouse to the index and ways in which these mechanisms can be used to trigger partial or full re-indexing of data.
Background
In all installations of CLAIMS Direct, data synchronization between the CLAIMS Direct primary data warehouse and on-site installations is driven by the tool apgup. In version 2.1, a new update daemon (apgupd) was introduced to facilitate background processing of new and updated data. The main roles this daemon plays include:
- Reconciling differentials between on-site data warehouses and CLAIMS Direct primary data warehouses
- Downloading the next available update package for processing within the on-site installation
- Processing the update package
- Loading data to the data warehouse
- Optionally en-queuing that load for indexing
For our topic, we will concentrate on the indexing queue as this drives the indexing process.
Index Queue
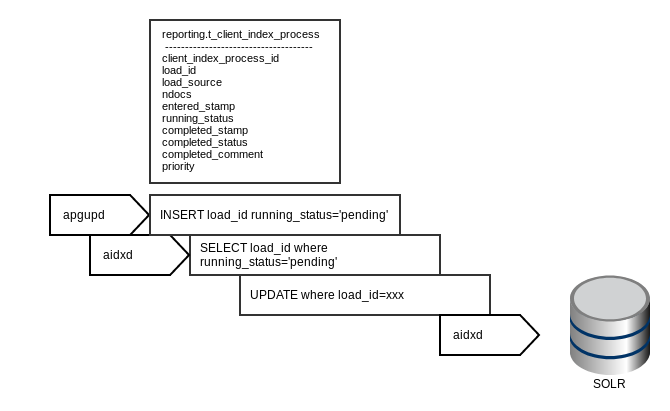
The indexing queue is a table inside the reporting schema: t_client_index_process. When apgupd completes the load into the PostgreSQL, a row is inserted into reporting.t_client_index_process with running_status = pending. The indexing daemon, aidxd, probes the table looking for the highest priority load_id to index. Upon finding an applicable load-id, aidxd proceeds to extract all publications associated with that load_id and index the documents into Solr.
The column priority influences which load_id is to be processed next. Higher priority load-ids are processed before lower priority ones. This can cause out-of-order processing as we will discuss below.
Re-indexing
Individual load_ids
At its simplest, re-indexing is just a matter of resetting a load_id in reporting.t_client_index_process
update reporting.t_client_index_process
set running_status='pending',
completed_stamp=null,
completed_status=null,
completed_comment=null
where load_id=123456;
The above SQL resets load_id 123456 so that the indexing daemon processes that load_id next. You can re-index any number of load_ids by resetting each of the rows.
Entire Data Warehouse
Unfortunately, resetting all the rows in reporting.t_client_index_process is not sufficient to re-index the entire contents of the data warehouse. This has to do with the fact that the table is empty upon initial load to the on-site instance as the population of reporting.t_client_index_process begins with the first update to the data warehouse. Each new update that is processed is queued. To that end, the most efficient way to queue the entire data warehouse for re-indexing is to select the entire xml.t_patent_document_values table and group by modified_load_id.
Before proceeding with the next set of SQL, please be sure both apgupd and aidxd are paused ( kill -s USR1 <pid> )
truncate table reporting.t_client_index_process; insert into reporting.t_client_index_process (load_id, load_source, ndocs, priority) select modified_load_id, 'REINDEX', count(*), -1 from xml.t_patent_document_values group by modified_load_id order by modified_load_id desc;
A few comments about the above statements:
- Truncating the table is required as the
load_idcolumn is unique. If you wish to save the contents of that table, simply use the pg_dump utility. - The
load_sourcecolumn is chosen at random. You can use any identifier you want as long as it doesn't exceed 64 characters. - The priority is set to -1 as in this example, re-index is less important than indexing new data.
Use Case
Changing Field Definitions
Modifying the CLAIMS Direct Solr Schema
The CLAIMS Direct Solr schema is a compromise between having every piece of the patent document searchable, having enough metadata stored to be retrievable in the search result set as well as indexing certain fields to be efficiently faceted. This compromise keeps the size of the index manageable while allowing efficient return of data from a search. Of course, the concept of manageable is subjective. There could very well be the need to have more fields returned during the search (stored=true) and other fields removed from storage but left searchable. In this use case, we will enable patent citations to be returned during the search. Regardless of CLAIMS Direct Solr package, we'll start editing the schema under <package>/conf-2.1.2. We are making a very simple change but one that requires a complete re-index of all documents having citations.
Be sure the indexing daemon (aidxd ) is paused.
The current field definition
<field name="pcit" type="alexandria_string" indexed="true" stored="false" multiValued="true" />
becomes
<field name="pcit" type="alexandria_string" indexed="true" stored="true" multiValued="true" />
To make this change effective, Solr needs to be restarted or the collection reloaded. For the standalone package, you would just need to restart Solr:
<package>/solrctl stop ; <package>/solrctl start
For the distributed package, first deploy updated configuration to the Zookeeper nodes.
cd <package> ./bootstrap-zookeeper.sh
Then reload all nodes:
cd <package> ./reload-collections
Setting up the Index Queue
Although we can go about re-indexing the entire data warehouse as outlined above, we want to be a bit more efficient and choose only the applicable documents, i.e., those that actually have citation data. To this end, we will find only load_ids that contain documents with citations and modify existing reporting.t_client_index_process rows as needed.
-- DELETE load-ids already processed delete from reporting.t_client_index_process where load_id in ( select distinct(modified_load_id) from xml.t_citations ); -- INSERT load-ids insert into reporting.t_client_index_process (load_id, load_source, ndocs, priority) select modified_load_id, 'CITATION-FIX', count(*), -1 from xml.t_citations group by modified_load_id
Again, setting priority to -1 allows new documents to be indexed as usual, and documents needing to be updated will be indexed with a lower priority.
Checking Re-Index Status
You can monitor the progress of the re-index by querying the reporting.t_client_index_process table as follows:
select priority, load_source, count(*) from reporting.t_client_index_process where running_status = 'pending' group by priority, load_source order by priority, load_source;
