Last week, I showed how KMX can classify a large numbers of patents. I looked at 3,961 patents published before June 23, 2012 using the search term “cloud computing”. I showed how to create a KMX Free Classifier using a training set. The free classifier allows me to classify the large data set based on terms that I select as relevant to the problem I am trying to solve. This enables me to perform deep analysis on large collections, and to quickly identify documents or trends that are very difficult to find otherwise.
The KMX classifier that I created is stored within KMX and can be used on new data sets. Based on the training examples I provided when doing the initial deep analysis, I create a classifier that can be used on other large collections, or on newly issued patents.
In this post, I use the classifier to explore the 176 US patents and applications that were published between June 24 and July 17. These documents contain the term “cloud computing”.
The results based on my classification scheme are as follows:
Looking at assignees, we see that IBM and Microsoft continue to lead in the area of cloud computing.
| authentication | 16 |
| business app | 25 |
| cloud storage | 30 |
| location | 20 |
| metering | 5 |
| operations | 17 |
| Other | 51 |
| virtualization | 12 |
| Grant Total | 176 |
Looking at assignees, we see that IBM and Microsoft continue to lead in the area of cloud computing.
| IBM | 26 |
| Microsoft | 13 |
| SAP | 10 |
| Korea Electronics | 6 |
| Cerner Innovation | 5 |
| Hon Hai | 5 |
| Nokia | 4 |
| Verizon | 4 |
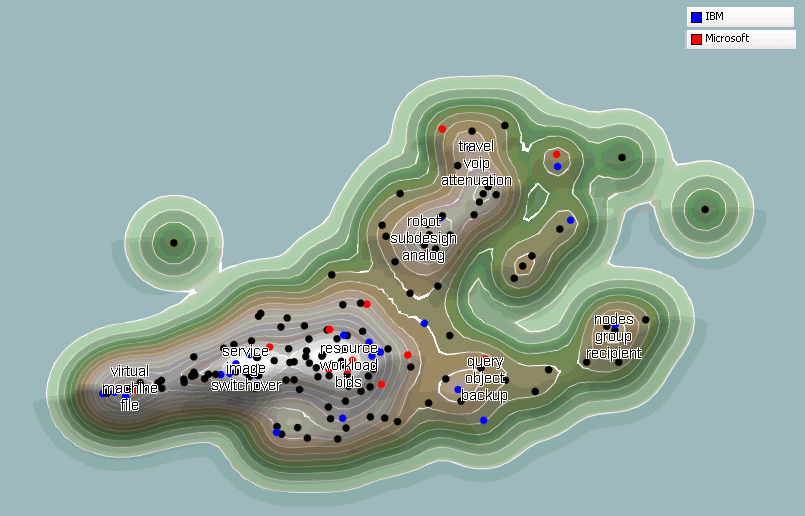
A landscape view, generated using KMX, is shown below. IBM and Microsoft are highlighted.
KMX Landscape of newly published Cloud Computing documents.
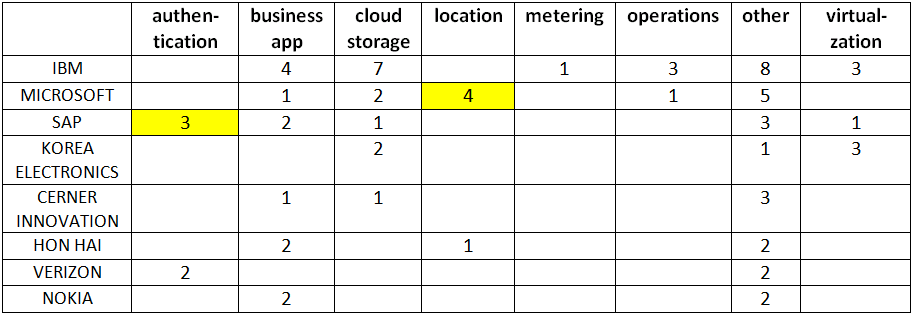
Looking at assignees together with my classification system, we see the following results:
Newly issued US "cloud computing" documents grouped by my KMX classifier and assignee name.
I exported the data results from KMX into Microsoft Excel and used pivot tables to prepare these tables. Using pivot tables, it is simple to zoom into individual cells. It is also easy to find assignees and filter by classification results from within KMX.
Above, I have highlighted the four newly issued “location” documents issued to Microsoft. Again, these were identified by KMX based on a training set in an entirely different set of documents. Here is an example:
Document: US-20120166077-A1
Assignee: Microsoft
Published: 20120628
Title: NAVIGATION INSTRUCTIONS USING LOW-BANDWIDTH SIGNALING
Assignee: Microsoft
Published: 20120628
Title: NAVIGATION INSTRUCTIONS USING LOW-BANDWIDTH SIGNALING
Also, SAP has three documents related to “authentication”. Here is an example of those:
Document: US-20120166177-A1
Assignee: SAP
Published: 20120628
Title: SYSTEMS AND METHODS FOR ACCESSING APPLICATIONS BASED ON USER INTENT MODELING
Assignee: SAP
Published: 20120628
Title: SYSTEMS AND METHODS FOR ACCESSING APPLICATIONS BASED ON USER INTENT MODELING
Newly issued patent are available to KMX users on the day of publication through the IFI CLAIMS Claims Direct web service. Using an existing KMX classifier on newly issued documents allows me to pinpoint documents of specific interest to my organization or my client – without having to read through the entire list. As a system for monitoring emerging trends and competitor activity, it is very powerful. If you would like more information, please contact us at info@ificlaims.com.
