In this blog, we will use the example of IP publications from class G06N/3 (computer systems based on biological models) to discuss the effectiveness of AI models in patent research and analysis. This category is defined as computing systems where the computation is based on biological models (brains, intelligence, consciousness, genetic reproduction) or is using physical material of biological origin (biomolecules, DNA, biological neurons, etc.) to perform the computation. The computation can be digital, analogue or chemical in nature.
This class was chosen because it is one of the fastest growing US patent application categories, as revealed by IFI's analysis earlier this year, and it integrates expertise from several domains that are evolving rapidly. The language used to describe novelties changes rapidly, and the challenge in examining applications and in taking freedom-to-operate decisions are growing.
It is easier to address the question of “what is NOT considered an AI search” than to try to define what AI search is. For the sake of this blog, AI search will be defined as any technology that involves the analysis of text using extended capabilities that do not rely solely on keywords. Text analysis could be exercised by:
-
Input:
- Triggering a search using descriptions or ideas rather than keywords.
-
Augmentation of the input by “understanding” and weighing contexts for relevance, automatically elaborating keywords submitted, and enriching keywords with relevant synonyms.
When relevant, “objective” augmentation of the input may be used, such as IFI’s assignee standardization, date calculations, etc.
-
Search target DBs (databases in which relevant information is searched for):
- Target DBs may be pre-processed and analyzed to prepare them for AI-based search, by enhancing aspects that are more relevant to the business case, for example, we may perform a special pre-processing to the Claims section of patent DBs.
- Analyzing the target DBs (i.e. patent databases) and creating concepts and idea maps; ontologies; creating catalogs; clustering/categorizing the DBs; etc.
-
Output:
- Determination of the relevance and ranking of the results, based on proximity in context.
Inputs are provided as free texts, and queries are computed in AI technologies.
Our solution implements an extraction of the ideas behind a given input text; we then generate queries automatically out of the ideas from the given context. To achieve this goal, we developed technologies that generate Associative Conceptual Maps (ACM), based on the input provided, in real-time.Search and ranking of results are offered using advanced heuristics and linguistic methods.
For the ACM of the input to be fully effective the target DB (patent databases) needs to undergo pre-processing to enable a search for ideas that are synonyms of those found in the input.
Results ranking is based, among other parameters, on understanding different parts of the patents and their unique contribution to the innovations and ideas behind the patent. We rely on IFI’s analysis and deconstruction of the raw data to better understand the patent and significantly improve ranking based on semantic relevance rather than statistical match/mismatch of keywords.Output refinement: “Search within results” and analysis are based on similar heuristics and influence one another. We allow the input of matter-meaningful text to narrow the sets of results.
This approach allows a broad conceptual first search and targeting of more specific aspects of inventions in the following searches. This is a time-saving exercise, as the input does not have to be studied for the selection of representative keywords. To that end we developed advanced search within results capabilities that bring all our AI power mentioned above to the search in the results stage as well.There are several cornerstones to the analysis process we practiced:
- Patent Informatics: we are constantly studying the structure of patent applications and the processes conducted toward granting. IFI CLAIMS is constantly improving and enriching the information in its databases, and following their newsletters is a good method for keeping up with updates.
- Semantic search: we use our proprietary algorithms that rely on association-based concept mapping. This process imitates the way we indentify subjects through intersecting maps of phrases that relate to the subject. For example, when we say, “add sugar and stir”, most people think of “teaspoon” or “spoon”. Creating such maps of a given text and calculating queries based on these maps allows us to build a set of queries that is tailor-made to the case at hand.
-
Semantic analysis of results: we use our AI technology and approach to analyze the set of results retrieved. This technique allows us to combine an automated semantic map of the results and a semi-automatic search in the results.
Once results are retrieved, the system analyzes the data and extracts main ideas and concepts. These ideas and concepts are then organized in clusters; a catalog of the top 15 dominant topics found is presented, and the user can request a focus on the findings that belong to any of those clusters.
We find several benefits in this approach: (1) visualization of the catalog provides an insightful landscaping map of the technological field at hand; (2) rather than trying to figure out what is concealed behind the data based on subjective prior knowledge of the researcher, the catalog offers a somewhat objective automatic discovery of the data. Naturally we consider it as a starting point for suggesting an initial lead for the researcher to investigate. - Analyze results: we combine the analysis of “structured information” (the fields that accompany each IP publication, such as title, various dates, etc.) with further inspection of the unstructured texts of the publication.
We addressed a seemingly complex set of questions:
- Identify the most significant subjects from the set of patents in the given class, in the past 12 years.
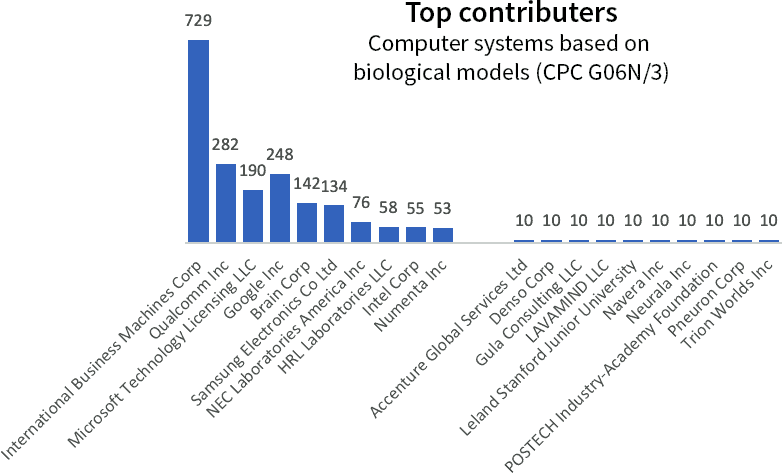
- Identify the strongest contributors of publications in this subject.
- Select a catalog entry that clusters publications relevant to a specific research (“Group C”).
- Identify the strongest contributors of publications in this subject.
- Assess the risk of infringement between the players that have contributed IP to G06N/3: for each of the top players, take the “summary of the invention” of the most relevant patent, and use it to perform a semantic search, free text search Group C.
Between 2009 and 2019, there were 3,953 applications filed at the USPTO and 1,863 granted patents.

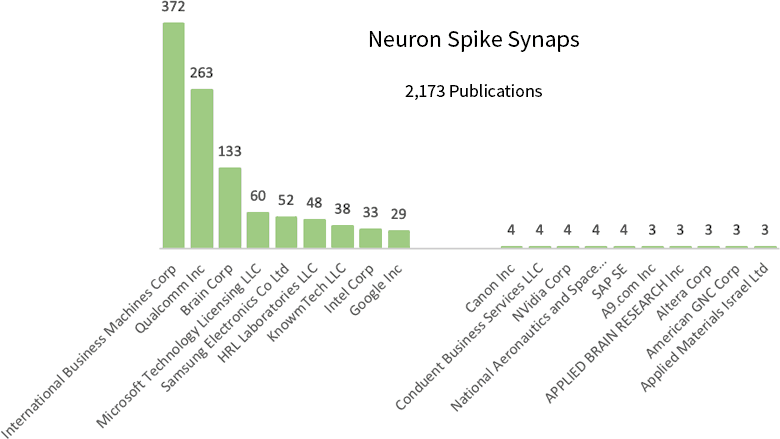
When creating a catalog of 15 subjects, we decided to look at “Neuron spike compute component connection weight”, which has 2,173 clustered publications.
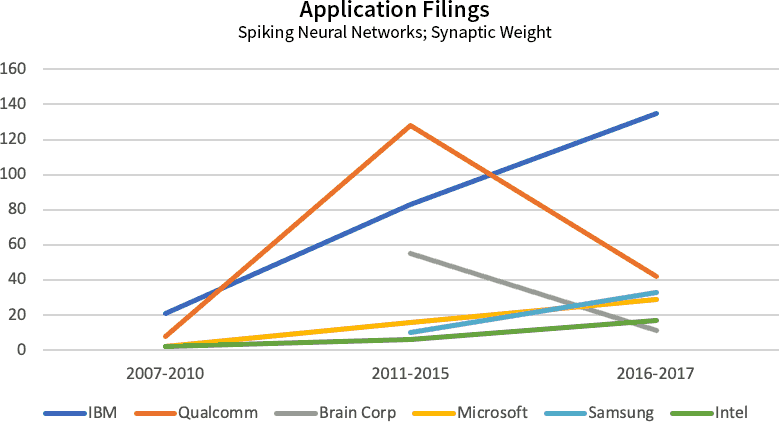
To assess the risk of infringement, we defined a “density index” (see details in the process description):
| When using patent of: (company, publication*) | The following contributors’ own publications with meaningful semantic proximity: |
|---|---|
| IBM, US-20120173471-A1 | IBM (233), Brain Corp (123), Qualcomm (118), KnowmTech (21), Cornell University (12), HRL labs (15), others |
| Qualcomm, US-20130046716-A1 | IBM (111), Brain Corp (85), HP Enterprise (10), Intel (13), University of Tennessee (9), others |
| Brain Corp, US-20130151448-A1 | Qualcomm (76), IBM (12), HRL Labs (2), Applied Brain Research (2), others |
| Intel, US-20180082176-A1 | IBM (178), Brain Corp (48), Qualcomm (17), University of Tennessee (9), Cornell University (7), others |
The process:
- Using a simple search, generate a space (list) of all the publications that have been classified as G06N/3 in the last 12 years.
- Use a semantic-based engine to create a catalog that displays the best representative subjects (the subjects that are referred to by most of the publications in the space).
- Use a semantic-based engine to sort the space by proximity to the subject matter that was selected as relevant to our investigation from the catalog computed in the previous stage.
-
“Density Index”: in order to assess the probability of infringement, we have used the following methodology:
- For each of the players, we selected a publication that is the “closest” to the subject of “Neuron spike component connection weight”; we have used a free-text semantic search of the summary of the invention to find patents that contain concepts with a “proximity” to this summary.
- The more publications we find that are close to the original patents (after cross-validation of relevance by selecting a representative patent for each player as an input for search), the greater is the likelihood of infringement, and the need to be exact and distinct when drafting claims.
- We can (although we have not done so for the current analysis) project the application of this density index over time to show proximity in time and order of application. We may also perform a referencing analysis, etc.
- From this analysis, we gain the following insight:
We analyzed the density of operation in this perceived segment and found overlap between the more distinct IP of each of the players, and matching IP of other players in the segment. The implications are that claim drafting should be precise and relatively narrow; FTO (freedom to operate) analysis should be carried out before commercialization, and cross-licensing is likely required.
Summary:
We have used the G06N/3 class to demonstrate the use of Inventive-IP’s semantic, concept-based research with patent informatics and the analysis of structured fields to identify key players, key concepts and market development in a highly populated IP space. We believe that our technology, along with IFI’s enriched patent databases, may provide fast responses to many of the needs of defensive and offensive IP management.
For service inquiries, contact Inventive-IP at info@inventive-ip.com
